

















「PDFからテキストを抽出」では、PDFからテキストを読み取り、変数化することができます。
PDFからテキストを抽出
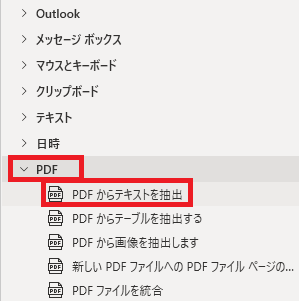
PDFからテキストを抽出は、アクションペインのPDFから追加できます。
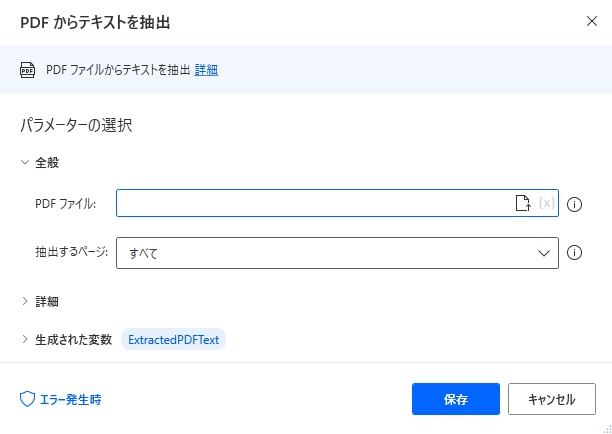
追加するとダイアログが表示されます。
PDFファイル
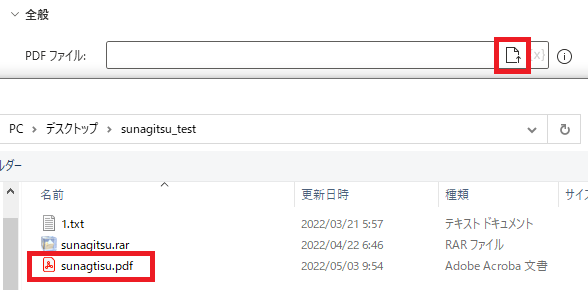
テキストを読み取るPDFファイルを指定します。
ファイルの選択アイコンから直接ファイルを選択すると、
ファイルの選択アイコンから直接ファイルを選択すると、
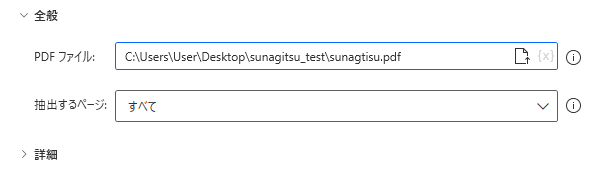
パスが入力されます。パスは直接書いてもいいし、パスの一部に{x}から変数を使用することもできます。
抽出するページ
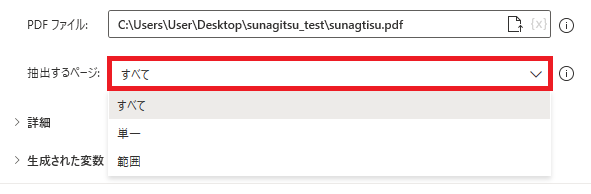
PDFのうち、抽出するページ範囲を指定できます。
すべてでは全ページが対象となり、
すべてでは全ページが対象となり、

単一では単一ページ番号で読み取るページを指定、
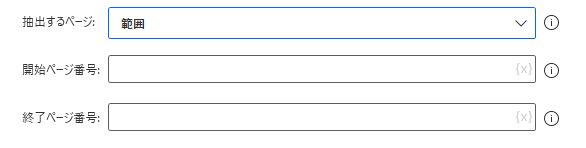
範囲では開始ページ番号と終了ページ番号で読み取る範囲を指定することができます。
パスワード

詳細の中にあります。PDFにパスワードがかかっている場合、ここに入力して解除できます。
生成された変数

変数には読み取ったテキストの内容が格納されます。
変数名をクリックして変更、{x}から他の変数に値を上書きすることができます。
変数名をクリックして変更、{x}から他の変数に値を上書きすることができます。
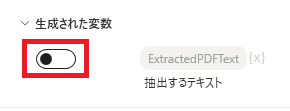
スイッチをオフにすると変数が生成されなくなります。
エラー発生時
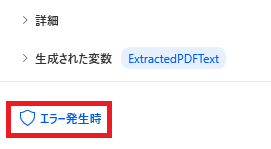
左下のエラー発生時から、
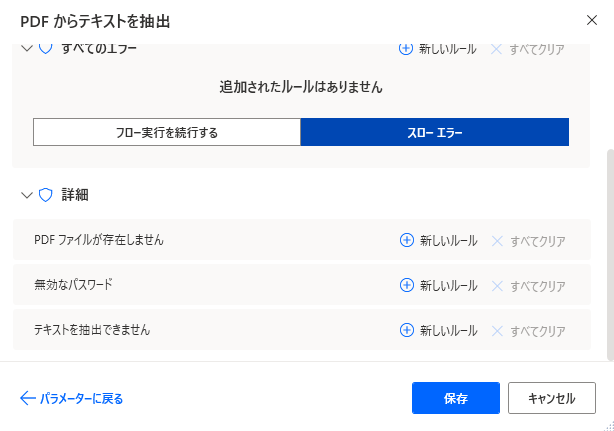
エラーが起きた時の処理を設定することができます。
詳細では、PDFが存在しない、パスワードが無効、テキストを抽出できない場合の対処を個別に指定できます。
詳細では、PDFが存在しない、パスワードが無効、テキストを抽出できない場合の対処を個別に指定できます。
実行例
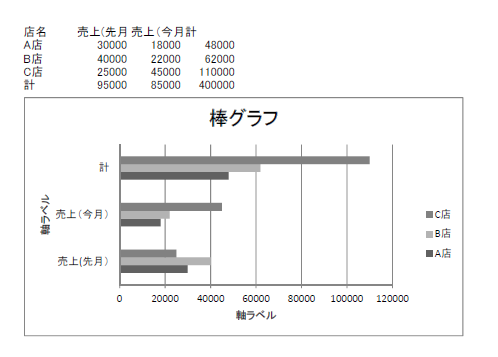
こういったPDFがあるとして、実際読んでみると、
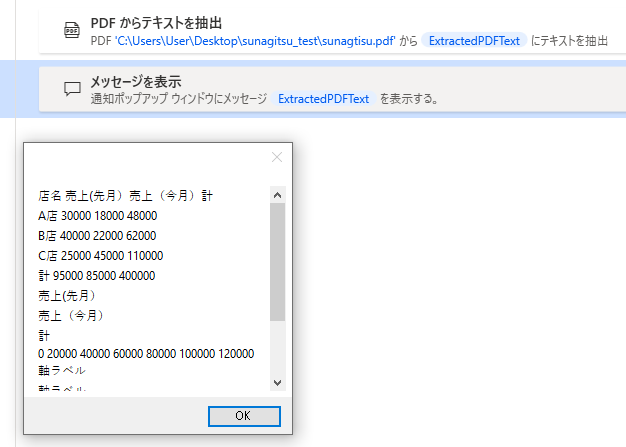
こんな具合で取得することが可能です。

Microsoft Power Automate Desktop(PAD)アクション、使い方一覧
Power Automate Desktopの使い方を機能・分類別に参照できるまとめです。
sunagitsune.com
2021.11.16


コメント