

















「PDFから画像を抽出」アクションを使うと、PDF内の画像を抽出することができます。
PDFから画像を抽出

とりあえず適当なPDFを作りました。これから画像を抽出したいと思います。
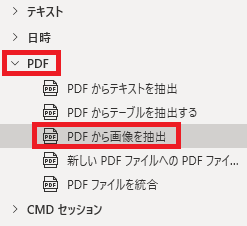
PDFから画像を抽出は、アクションペインのPDFから追加できます。
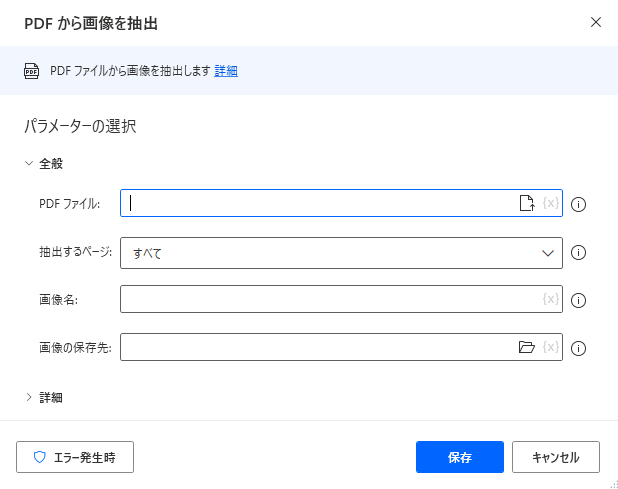
追加するとダイアログが表示されます。
PDFファイル

画像を抽出するPDFファイルを指定します。直接入力してもいいですし、ファイルの選択アイコンで指定すればパスが自動で入力されます。
抽出するページ
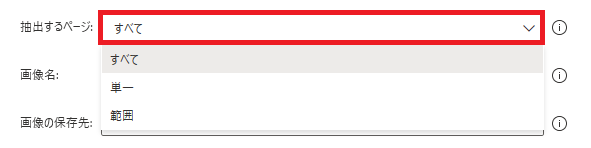
PDFのどのページから画像を抽出するかを、すべて、単一、範囲から指定できます。

単一なら単一ページ番号で抜き出すページ、

範囲なら開始ページ番号と終了ページ番号で抜き出す範囲を指定できます。
画像名

抽出する画像に名前をつけることができます(実際はこの名前の後に数字が付きます)。
画像の保存先

画像の保存先をパスで指定できます。フォルダーの選択からフォルダを選ぶとパスが自動で入力されます。
パスワード

もしPDFにパスワードがかかっている場合は、ここでパスワードを入力しておきます。
実行結果
実際に実行すると、こんな感じで名前_数字形式で画像が作成されます。
数字毎にPDF内の画像が割り当てられて保存されていることが確認できます。
エラー発生時
左下のエラー発生時では、エラー時の対応を指定することができます。
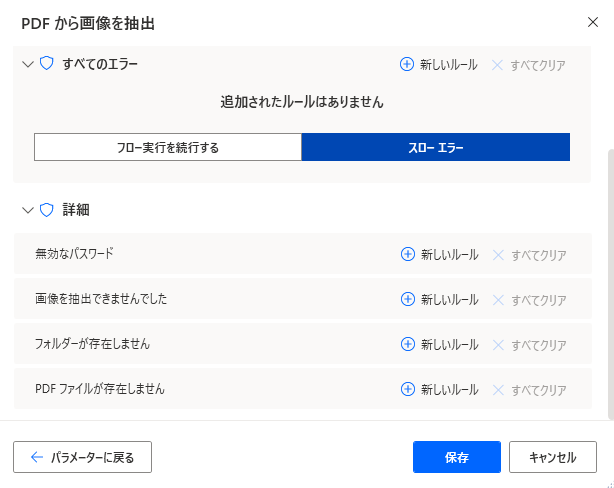
詳細では無効なパスワード、画像を抽出できない、フォルダーが存在しない、PDFファイルが存在しない場合を指定できます。

Microsoft Power Automate Desktop(PAD)アクション、使い方一覧
Power Automate Desktopの使い方を機能・分類別に参照できるまとめです。
sunagitsune.com
2021.11.16


コメント