




















「PDFからテーブルを抽出する」では、PDFファイルからテーブル部分を読み取り、DataTable形式で取得することができます。
PDFからテーブルを抽出する

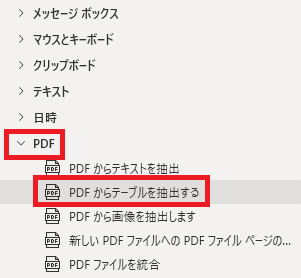
PDFからテーブルを抽出するは、アクションペインのPDFから追加できます。

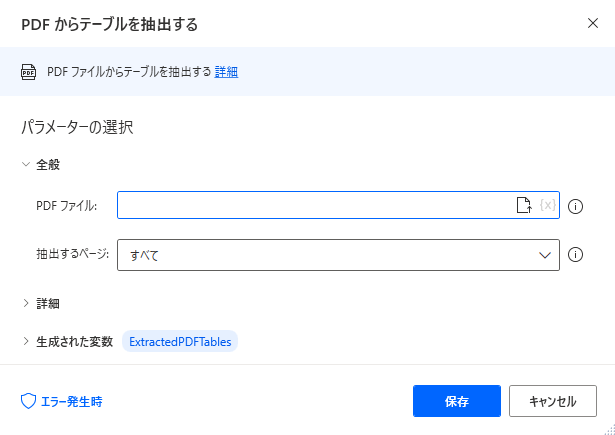
追加するとダイアログが表示されます。
全般

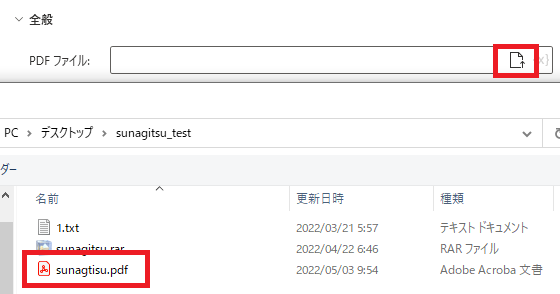
テーブルを読み取る対象となるPDFを指定します。ファイルの選択アイコンからファイルを選択すると、

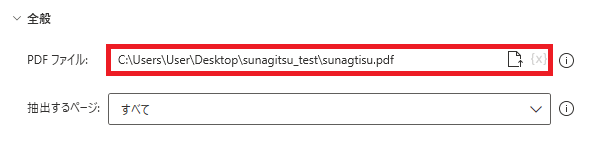
パスが入力されます。パスは直接書いてもいいし、パスの一部に{x}から変数を使用することもできます。
抽出するページ

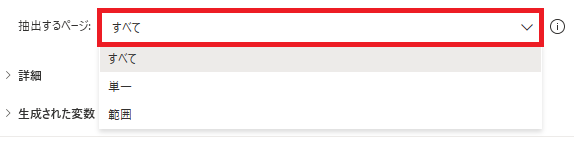
テーブルを読むページを指定します。すべてでは全ページが対象となります。


単一では単一ページ番号で読み取るページを指定、

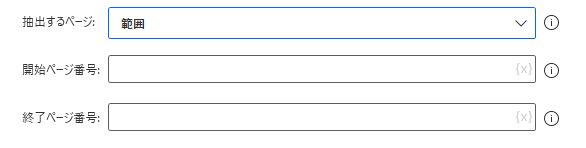
範囲では開始ページ番号と終了ページ番号で読み取る範囲を指定することができます。
詳細

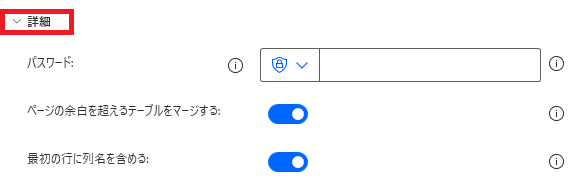
詳細から、以下の設定が可能です。
パスワード

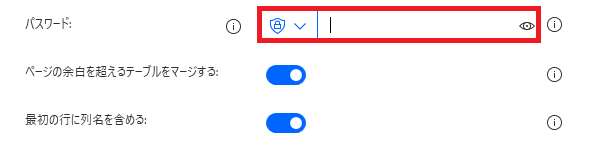
PDFがパスワードで保護されている場合、それを解除するためのパスワードを指定できます。
保護されてない場合は空欄でOKです。
保護されてない場合は空欄でOKです。
ページの余白を超えるテーブルをマージする

マージ=結合。つまりページをまたいだテーブルをくっつけるか、分離して取得するかを指定できます。
最初の行に列名を含める


テーブルの一行目を見出し(列名)として扱うかどうかを指定できます。
生成された変数

変数の名前をクリックして変更可能です。{x}から別の変数に値を上書きすることもできます。

スイッチをオフにすると変数が生成されなくなります。
エラー発生時

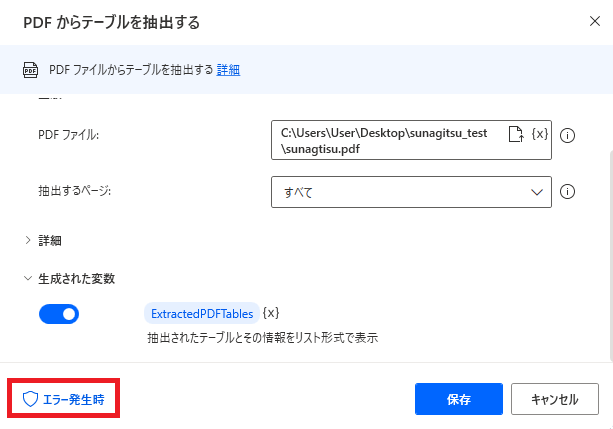
エラー時の処理を設定できます。

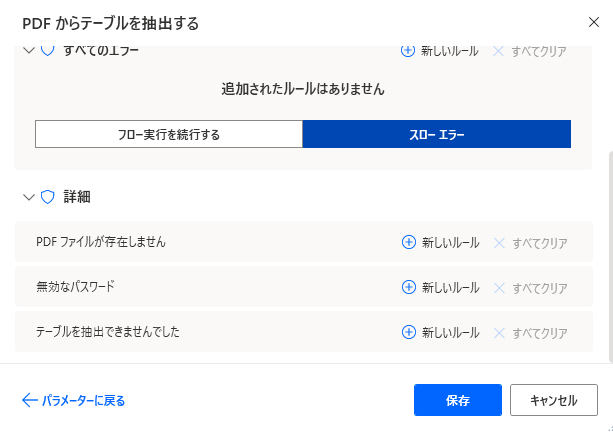
詳細では、PDFが存在しない、パスワードが無効、テーブルを抽出できない場合の対処を個別に指定できます。
実行例

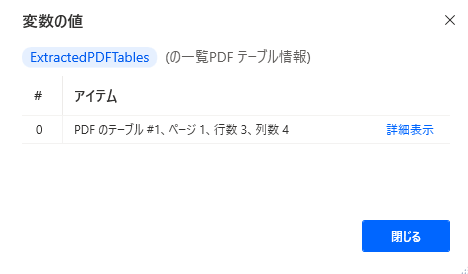
取得される変数(DataTable形式)は、塊としてはテキストとなり、

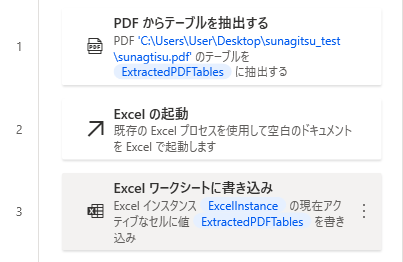
たとえば取得した変数をそのままExcelに書き込んでも、


こんな感じのよくわからない状態になります。

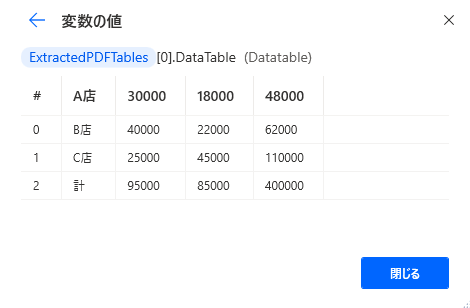
DataTableはこんな感じで中にデータが入っているのですが、

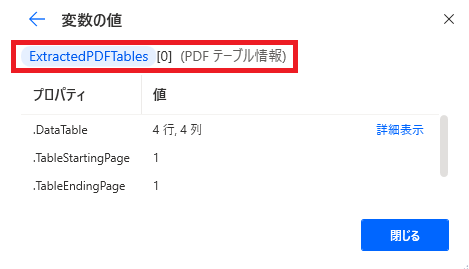
PDFからテーブルを抽出するで取得したテーブルにはそれぞれ0,1,2…とナンバーが振られるので、(変数名)[0]でひとつめのテーブルを指定することができ、

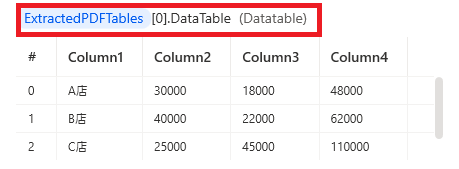
さらにその後ろに.DataTableを付けると、テーブルの中身を取得することができます。

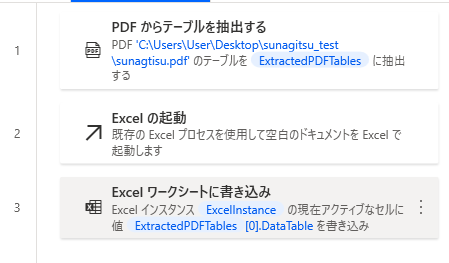
なので仮にテーブルがひとつしかない場合、図のようにすれば、

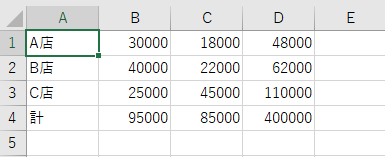
テーブルの中身を取得することができます。
Pdf.ExtractTablesFromPDF.ExtractTables PDFFile: $'''C:\\Users\\User\\Desktop\\sunagitsu_test\\sunagtisu.pdf''' MultiPageTables: True SetFirstRowAsHeader: False ExtractedPDFTables=> ExtractedPDFTables
Excel.LaunchExcel.LaunchUnderExistingProcess Visible: True Instance=> ExcelInstance
Excel.WriteToExcel.Write Instance: ExcelInstance Value: ExtractedPDFTables[0].DataTable
# [ControlRepository][PowerAutomateDesktop]
{
"ControlRepositorySymbols": [],
"ImageRepositorySymbol": {
"Name": "imgrepo",
"ImportMetadata": {},
"Repository": "{\r\n \"Folders\": [],\r\n \"Images\": [],\r\n \"Version\": 1\r\n}"
}
}


Microsoft Power Automate Desktop(PAD)アクション、使い方一覧
Power Automate Desktopの使い方を機能・分類別に参照できるまとめです。

sunagitsune.com
2021.11.16



コメント