




















ComfyではCheckpointと呼ばれる学習データを読み込むことで、作成する画像の画風を変更することができます。
※モデルのDLには権利者とのトラブル、ウィルス感染などのリスクが存在します。アダルト画像や有名人に対するセーフガードもStable Diffusionにはありません。ご利用は自己責任でお願い致します。
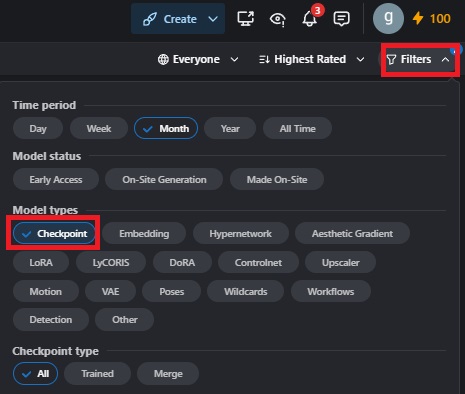
Checkpointの変更




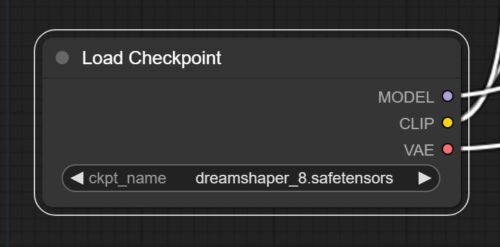
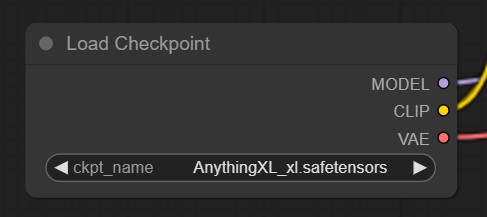
ckpt_nameが読み込むmodel files(Checkpoint)の名前となり、

Checkpointを変えたら、あとは同じように画像を生成するだけです。




Checkpointの追加
Stability Matrixの場合




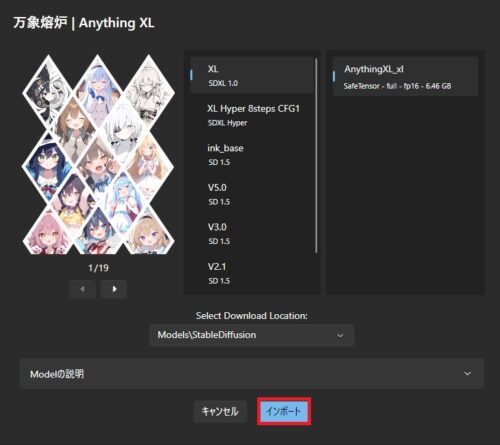
バージョン選ぶとサンプル画像も変わります。


Checkpointの確認、保管場所


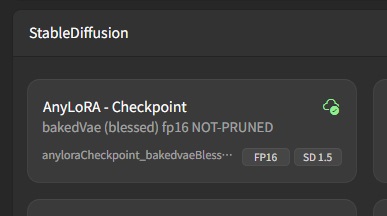
Checkpointの拡張子には、.ckptと.safetensorsの二種類があります。




保管場所は私の環境では(インストール先)\stable diffusion\stabilitymatrix\Data\Modelsでした。
(インストール先)\stable diffusion\stabilitymatrix\Data\Packages\ComfyUI\models\checkpointsにファイル入れても認識されるっぽいですが、こっちだと他のパッケージとモデル共有できないと思われます。
GUIによって構成は変わるはずですが、大体似たような場所にあると思われます。
CivitAI

Hugging faceというのもありますが一旦スルーします。

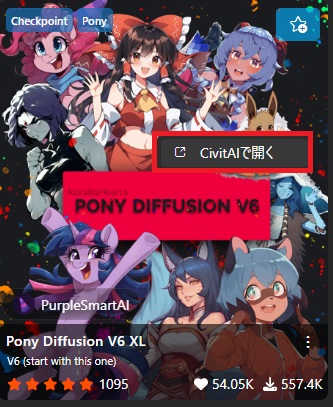

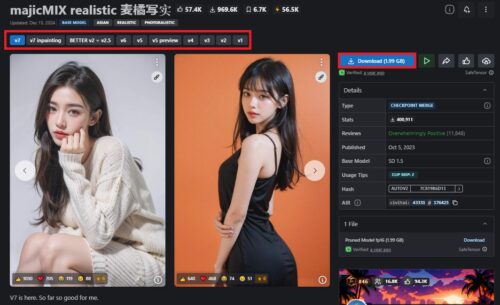
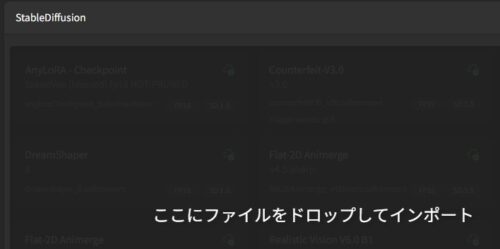
バージョンを選んでDLすればいいのは同様ですが、直接落とした場合は自分でCheckpointフォルダに入れるなり、Stability Matrixにドラッグ&ドロップするなりしてインポートする必要があります。

ここでは規約の詳細については割愛。




あと、Checkpointはひとつあたり数GB容量食います。
Load CheckpointのMODEL、CLIP、VAE
要はmodel filesにはこの三種類のデータが内包されており、それを別々の処理に投げています。

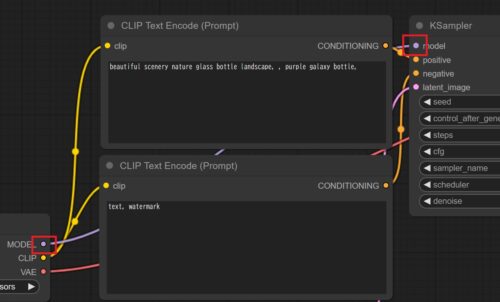
MODELは潜在空間で①入力された画像(なければ空白の画像)をノイズにする②ノイズにプロンプトを加えて逆方向にノイズを除去し、画像を生成する というような働きをします。MODELを使用してこのノイズ/デノイズを行うのがKSamplerというノードなので、デフォルト設定ではKSamplerに直接送られます。

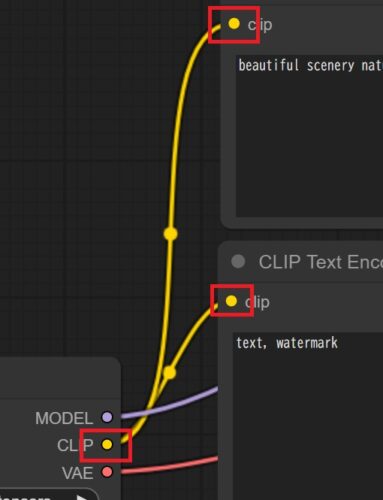


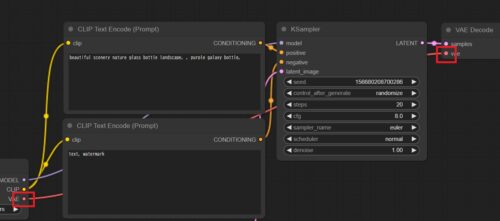
基本的な構成では、デコード処理を行うVAE DecodeにモデルのVAEは直接つながれます。
まとめると、普通の画像をVAEが潜在空間に落とし、潜在空間の画像がMODELによってぐちゃぐちゃにされ、そこにCLIPの指示が足され、MODELによって潜在空間に画像が再構成され、VAEがそれを普通の画像に戻します。
ComfyUIへのLoad Checkpointの追加

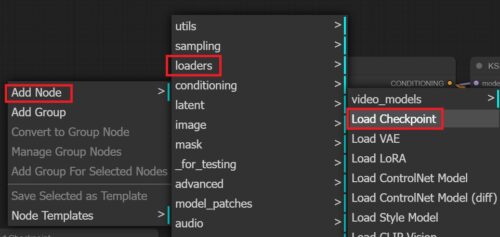

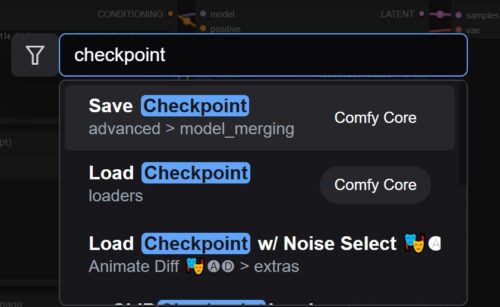
バージョンについて(SD1.5、SDXLなど)
Stable Diffusionのモデルには大別されるバージョンがあります。
SD1.5用のコントロールネットなどはSDXLのcheckpointでは使えず、別にDLする必要があります。
SD1.5
SDはStable Diffusionのイニシャルです。
最初期バージョンとしてv1.4が2022年8月、10月に改良版としてv1.5が発表され、1.x系の標準モデルとなりました。
動作が軽量かつ、比較的高品質な画像の生成が可能です。現状最も広く使われるモデルです。
SD2.1
SD2.x系では解像度やテキスト理解力を強化し、よりフォトリアリスティックな表現が強化されました。反面、イラスト系はやや苦手です。
NSFW系のイラストも出にくくなっています。2.0が2022年11月、2.1が12月に発表されました。
SDXL
1→2→3とは異なる設計でトレーニングされたバージョンです。
SD1.5が苦手とする複雑な構図、細部(指など)の描写に対応し、解像度も改善されています。2023年6月にベータ版、7月に正式公開されました。
Pony、Animagine XL、illustriousや、SDXL Lightning、Hyper-SDXLなどの派生モデルがあります。
SD3.5

LoRA(軽量model)の追加

LoRAを使用すると、さらに画風やポーズを特化させていくことが可能です。




コメント